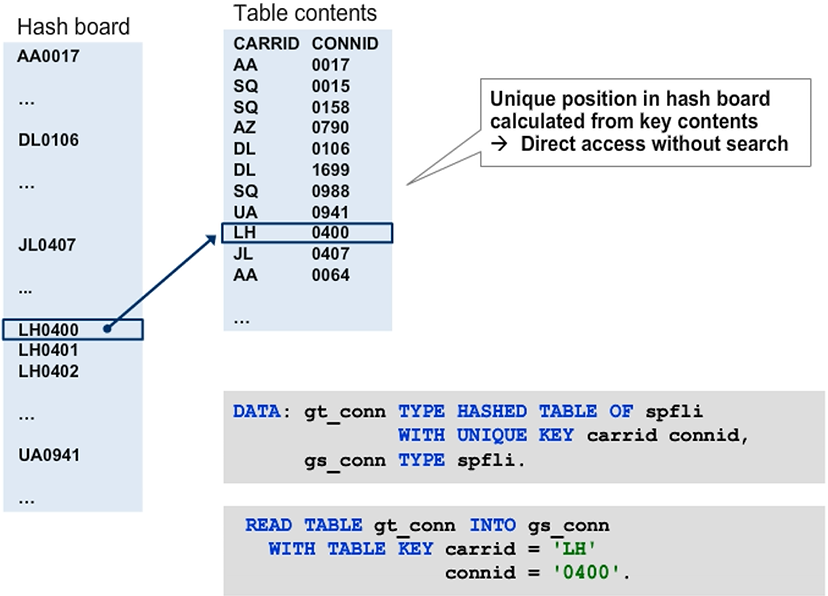
Using Standard, Sorted, and Hashed Tables
Internal Table Categories
When you define internal tables, you can select one of three table kinds: standard, sorted, or hashed. The table kind determines how the runtime environment stores data in the table and how the application program can access this data.
Storage is simplest for standard tables and therefore access to the data is particularly easy. When you use one of the other table kinds you hardly gain anything in terms of functionality. You even lose some access types that use indexes and which are not possible with sorted and hashed tables.
The main reason for using sorted and hashed tables is not to gain additional features but to improve efficiency when accessing large internal tables. The one additional feature is the possibility to define a unique key for sorted and hashed tables.
Standard Tables
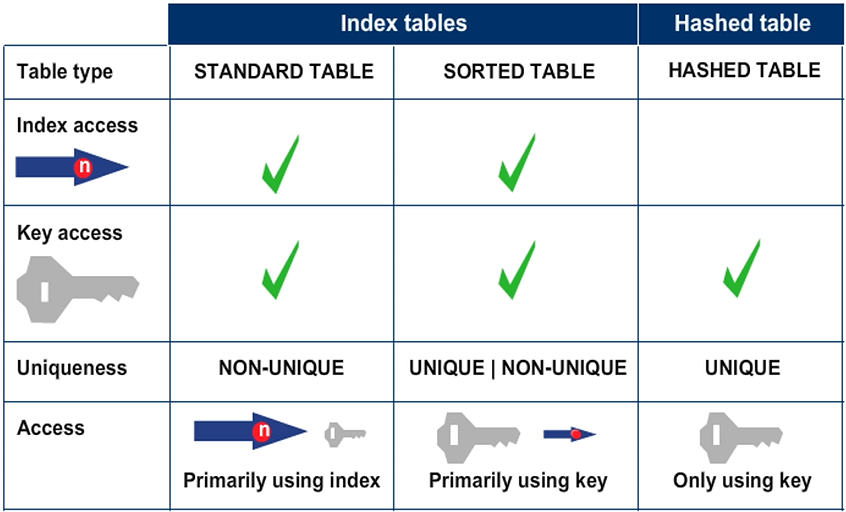
Standard tables are managed internally using a table index (line numbers). You can append new lines at the end of the table or insert them at specific positions. The lines within the internal table can be in any sequence and, consequently, the system has to search the entire table sequentially during a key access. While this can be done relatively quickly for small tables, the search effort increases linearly with the number of lines.
Note: If the internal table is explicitly sorted by using the SORT statement, the BINARY SEARCH addition can significantly speed up access.
Sorted Tables
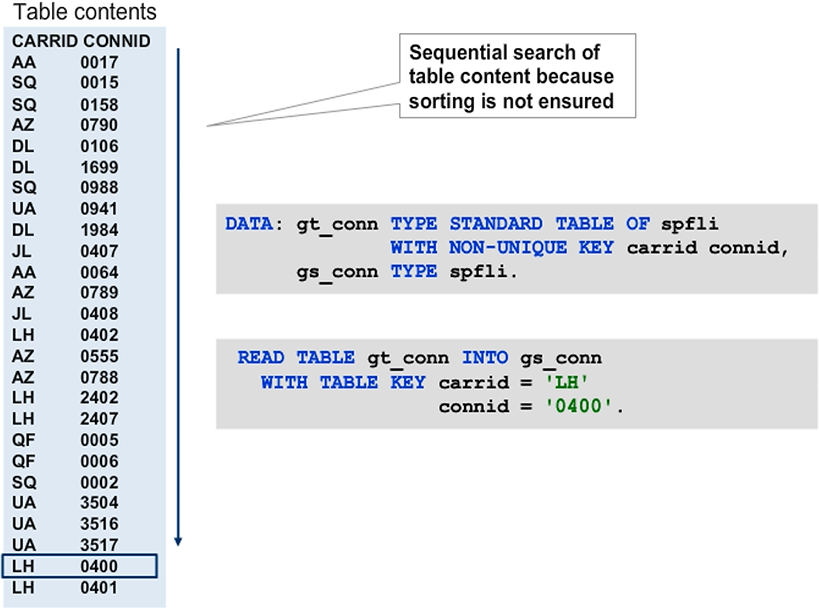
Like standard tables, sorted tables are managed using a table index. The entries are always sorted in ascending order by the table key. As a result, the system automatically performs a binary search during table key accesses.
Based on the total number of lines, the runtime environment determines an index in the middle and reads a line by index access there. By comparing the key field values of this line with the search criteria, the system determines whether the sought entry is before or after the current line. This step halves the data in a single step and is repeated until the sought entry is found or the system determines that no entry in the table matches the criteria.
Hint: If the sorted table has a non-unique key, several lines could match the criteria. The result of sorting is that all lines with the same key are in a contiguous block, and the system always returns the first line of the block, that is, the one with the smallest index.
Hashed Tables
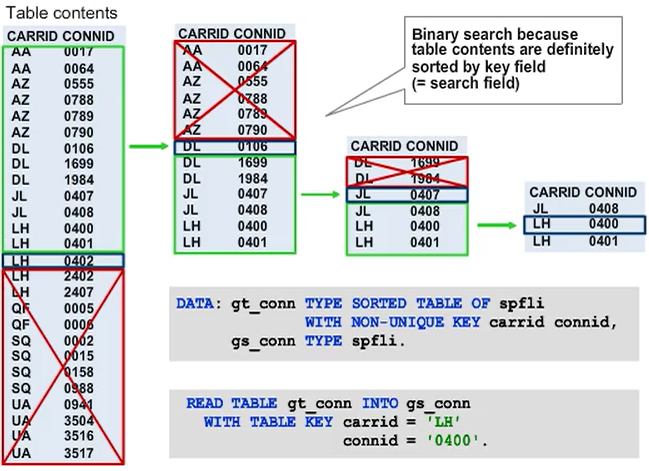
Hashed tables are managed internally using a hash algorithm. To enable this, a hash board is created in addition to the actual table and the memory addresses of the table lines are managed in that table. Whereas the table contents are completely unsorted, a hash function makes it possible to directly calculate the position of the entry in the hash board from the key values. Accordingly, the key of a hashed table must always be unique.
The effort required to calculate the position in the hash board and then read the table line is identical for all lines, regardless of the number of table entries. The entries in the hash board are not consecutive but are instead spread over a certain memory area. These gaps make it possible to insert additional lines later. The hash function that is used determines how large the gaps are. If the system calculates that the entries in the hash board are too close to one another when inserting a line, it reorganizes the hash board. To do so, the positions are calculated with a different hash function that distributes the entries over a larger memory area.
Hint: Loops (LOOP ... ENDLOOP) ignore the hash board and search the table contents directly. The content is unsorted, but for this purpose, it can be sorted by using the SORTstatement.
Index Access and Key Access
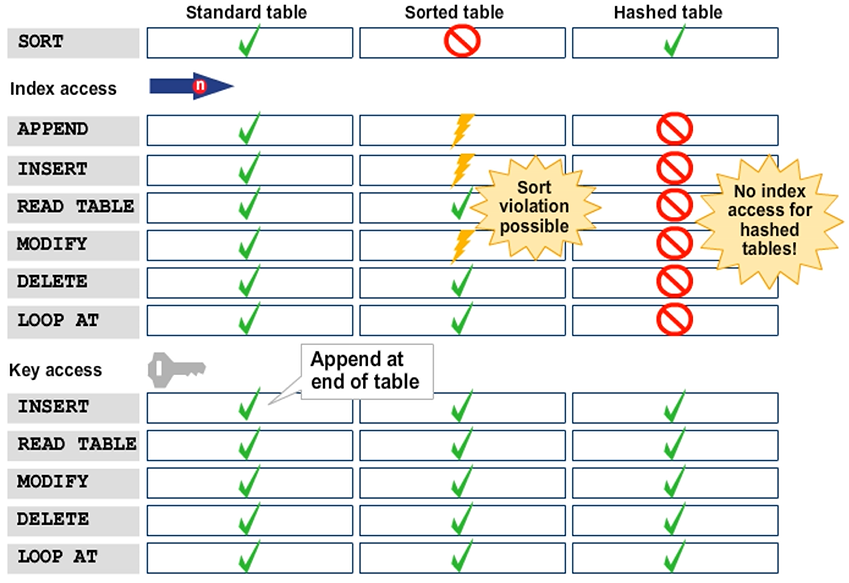
Single Record Read Accesses
Single records from internal tables are read using the READ TABLE statement.