Defining cluster and pooled tables
Cluster Tables and Pooled Tables
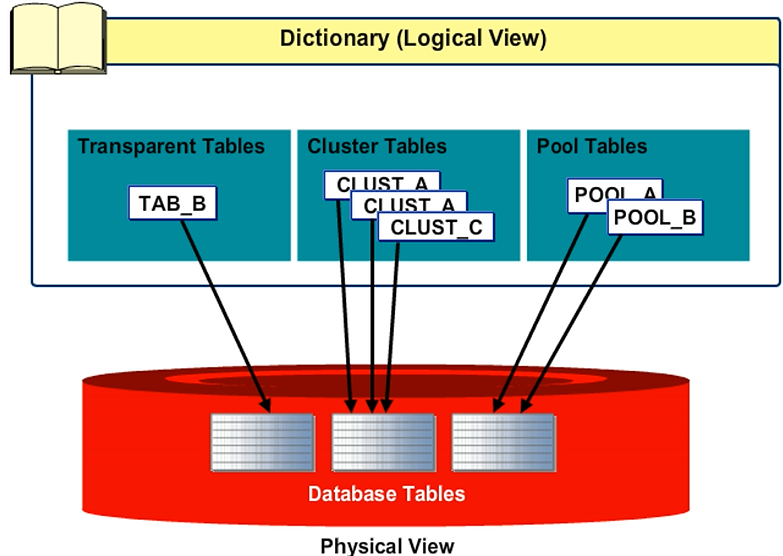
In addition to transparent tables, where the definition in the ABAP Dictionary and the database are identical, there are pooled and cluster tables in the SAP system. Pooled and cluster tables are characterized by the fact that several tables logically defined in the ABAP Dictionary are combined in a physical database table (table pool or cluster). SAP uses the pool tables and cluster tables mostly for system-internal data. Business data should be stored in transparent tables.
Cluster Tables
In cluster tables, you store functionally dependent data, which is divided among different tables, in one database table. Accordingly, the intersection of the key fields of the cluster tables form the key of the table cluster, known as the cluster key.
The data dependent on one cluster key is stored in the VARDATA field of the table cluster. If the VARDATA field does not have the capacity to take on all the dependent data, the database interface creates an overflow record. The PAGNO field guarantees the uniqueness within the table cluster.

Pooled Tables
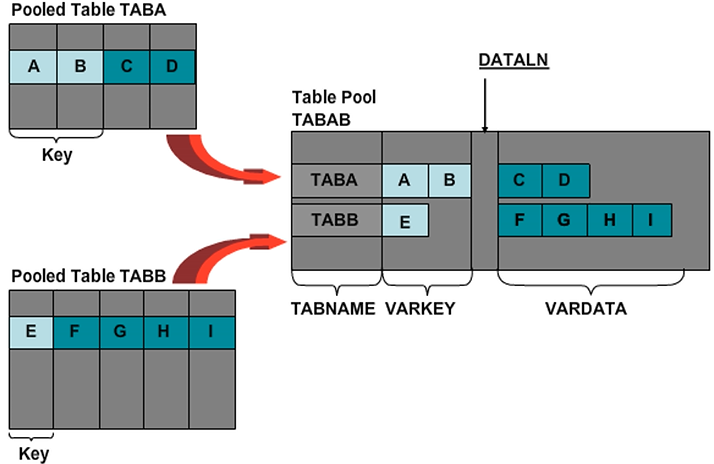
A table pool, as opposed to a table cluster, stores data records from the tables defined in the ABAP Dictionary that are not dependent on one another. You would like to combine small SAP tables in one database table.
In the example in the figure, you can see there are no common key fields between TABA and TABB. Despite this, the TABAB table pool stores the data records from TABA and TABB.
The key for a data record of the TABAB table pool consists of both the TABNAME and VARKEY fields. The TABNAME field assumes the name of the pooled table. The VARKEY field consists of the concatenation of the key fields of the pooled table. For this reason, the key fields of a pooled table must be of the type C.
The database interface stores the non-key fields of the pooled tables in an unstructured way, in the VARDATA field in compressed form. The DATALN field contains the length of the VARDATA field.
In the pooled table, the technical settings are exactly the same as transparent table. The only addition is the Convert to transparent table indicator. You can convert the pooled table into a transparent table with this indicator.
Advantages and Disadvantages of Pooled and Cluster Tables
The primary advantage of pooled and cluster tables is that the data can be stored in compressed form in the database. This reduces the memory required as well as the network load.
Combining tables into pooled tables or cluster tables results in fewer tables and fewer table fields (due to data compression). The result is that fewer different SQL statements need to be carried out.
Because pooled and cluster tables are not stored as separate tables in the database, administration is simpler. With cluster tables, functionally dependent data is read together, which results in fewer database accesses. The main disadvantage is that database functionality is restricted. It is not possible for non-key fields to be created as an index. There are neither primary indices nor indices on a subset of the key fields. The use of database views or ABAP joins is also ruled out, as are table appends. You can access the data in pooled or cluster tables only by OPEN SQL (not Native SQL).
For pooled tables, only the WHERE conditions for key fields are transferred to the database. In the case of cluster tables, only the WHERE conditions for the fields of the cluster key (subset of the key fields) are transferred.
ORDER BY (or GROUP BY) clauses are not transferred for non-key fields.
You need longer keys than semantically necessary for pooled tables.